阿里开源首个全模态大模型Qwen2.5-Omni,实时,智能,自然
2025-03-28 11:43:17
阿里开源首个全模态大模型Qwen2.5-Omni,实时,智能,自然
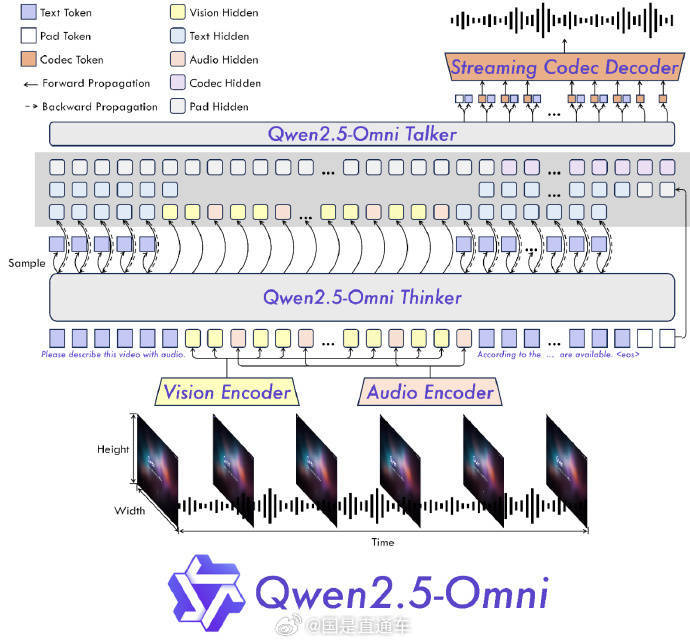
27日凌晨,阿(a)里巴巴发布并开源首(shou)个端到(dao)端全模态(tai)大模型通(tong)义千问Qwen2.5-Omni-7B,可同时处理文本、图像(xiang)、音(yin)频和视频等多(duo)种输入,并实时生(sheng)成文本与(yu)自然语音(yin)合成输出。在权威(wei)的多(duo)模态(tai)融合任务OmniBench等测评中(zhong),Qwen2.5-Omni刷新业界纪录,全维(wei)度远超谷歌的Gemini-1.5-Pro等同类模型。据悉,Qwen2.5-Omni以接近人(ren)类的多(duo)感官(guan)方式“立体”认知(zhi)世界并与(yu)之实时交互,还能通(tong)过(guo)音(yin)视频识别情(qing)绪,在复杂任务中(zhong)进行更智能、更自然的反(fan)馈与(yu)决策(ce)。现在,开发者和企业可免费下载商用Qwen2.5-Omni,手机等终端智能硬件也可轻松部(bu)署运行。